Модель Text2Vec
Модель Text2Vec преобразует текстовые столбцы датафрейма в векторные представления фиксированной размерности.
Полученные числовые вектора можно использовать как входные признаки для стандартных моделей машинного обучения на табличных данных — например, для кластеризации или классификации.
Основная идея
Внутри Text2Vec обучается модель Word2Vec (из библиотеки gensim) на вашем текстовом корпусе, а затем для каждой строки датафрейма считается средний вектор слов, присутствующих в этой строке.
Как работает внутри
Основные этапы:
- Подготовка данных
- Все текстовые поля конвертируются в списки слов.
-
Каждая строка считается как отдельный "документ" или "предложение".
-
Обучение Word2Vec
- Модель Word2Vec обучается на всем корпусе текстов.
-
Корпус — это список списков слов.
-
Векторизация строк
- Для каждой строки собираются все слова.
- Для слов, имеющихся в словаре Word2Vec, берутся их эмбеддинги.
- Итоговый вектор строки — среднее арифметическое всех эмбеддингов слов.
- Если в строке нет ни одного слова из словаря — возвращается нулевой вектор.
Основные параметры
| Параметр | Описание |
|---|---|
vector_size |
Размерность выходного вектора. Важно: слишком маленькое значение ухудшает качество, особенно при малом датасете. |
sg |
Архитектура обучения: 0 — CBOW, 1 — Skip-gram. |
window |
Размер окна контекста вокруг слова. |
Важно: При слишком маленьком датасете и слишком большом
vector_size, модель может выдавать некачественные или даже полностью нулевые вектора.
Подробно о параметре sg: CBOW vs Skip-gram
Параметр sg (от "skip-gram") определяет, какая архитектура Word2Vec будет использоваться при обучении векторных представлений слов.
| Значение | Архитектура | Описание |
|---|---|---|
0 |
CBOW (Continuous Bag of Words) | Модель пытается предсказать текущее слово, зная слова из его контекста (окружающие слова). Быстрее обучается, лучше для частых слов. |
1 |
Skip-gram | Модель пытается предсказать контекст (окружающие слова), зная текущее слово. Лучше работает с редкими словами и на малых датасетах, но медленнее. |
Как это влияет на Text2Vec
CBOW (sg=0)
- Плюсы:
- Быстрая сходимость
- Хорош для крупных датасетов
-
Предпочтителен, если тексты длинные и слов много
-
Минусы:
- Хуже работает с редкими словами
- Может "сглаживать" семантику
Skip-gram (sg=1)
- Плюсы:
- Лучше качество векторизации на малых и средних датасетах
-
Лучше захватывает связи редких слов
-
Минусы:
- Более медленное обучение
- Требует больше ресурсов
Как выбрать архитектуру для своей задачи?
| Если... | Рекомендация |
|---|---|
| У вас маленький корпус текстов (до ~10 000 строк) | Используйте Skip-gram (sg=1), чтобы лучше "поймать" даже редкие слова |
| У вас большой корпус (от ~100 000 строк и выше) | Можно использовать CBOW (sg=0) для скорости |
| Если целевая задача связана с редкими словами | Лучше Skip-gram |
| Если цель — быстрое приближённое представление | Можно CBOW |
Итог
Параметр sg — это ключевой выбор между двумя подходами к обучению Word2Vec, и он напрямую влияет на то, насколько хорошо будут обучаться эмбеддинги слов с учетом доступного размера данных и целей задачи.
В Text2Vec этот параметр можно свободно настраивать через параметры модели.
Пример сценария использования
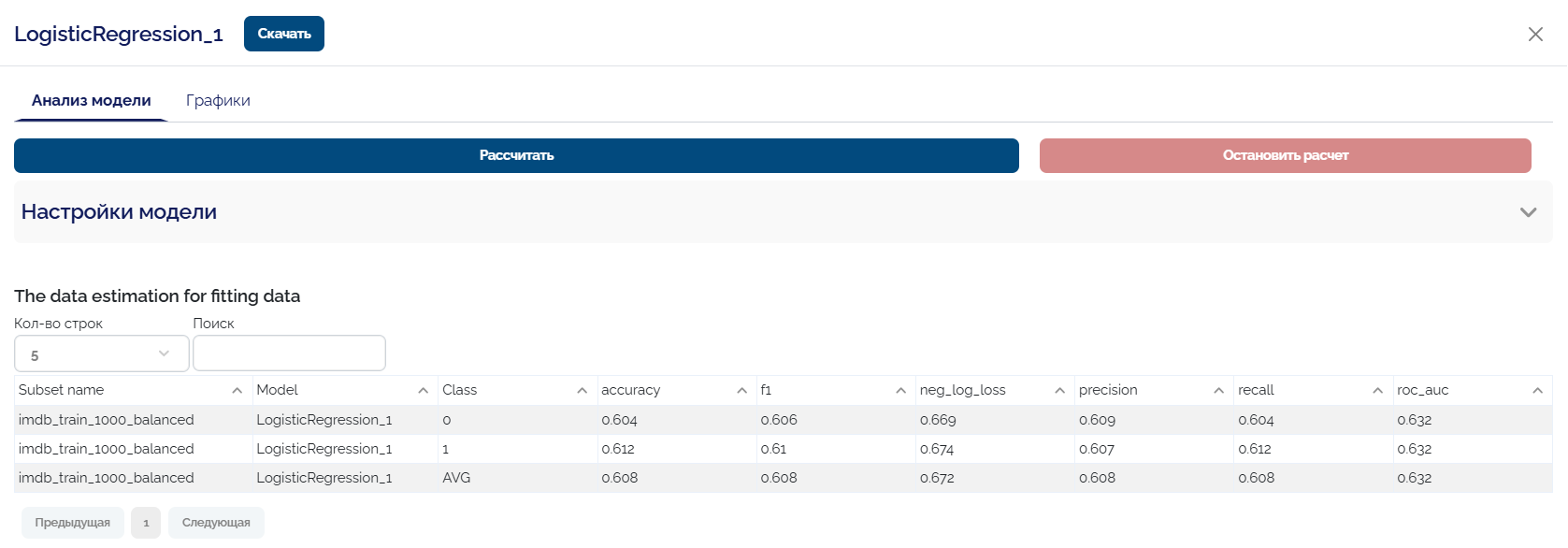
Классификация отзывов с IMDb
-
Входные данные: текстовые отзывы (например, положительные/отрицательные метки).
-
Пайплайн:
- Применяем Text2Vec, чтобы превратить текст в вектора.
- Обучаем стандартный классификатор (например,
LogisticRegression,RandomForestилиLightGBM).

- Оцениваем качество.