Модели BERT на платформе SMILE
На платформе SMILE в данный момент имеются две модели BERT:
- BertTokenizer для предобработки и векторизации текстовых данных на основании словаря модели BERT.
- BertClassifier для бинарной/многоклассовой классификации текстовых данных
Модель "BertTokenizer"
BertTokenizer используется для преобразования текстовых данных в токены с помощью словаря модели BERT.
Модель "BertTokenizer" имеет следующий параметр:
- columns - столбец с документами, который необходимо токенизировать.
Выходной результат:
Модель возвращает матрицу, содержащую токенизированные признаки.
После данную матрицу можно использовать для задач NLP, таких как: - Классификация текста - Анализ тональности - Ответ на вопросы - Распознавание именованных сущностей (NER) - Машинный перевод (в сочетании с другими моделями)
Пример использования модели:
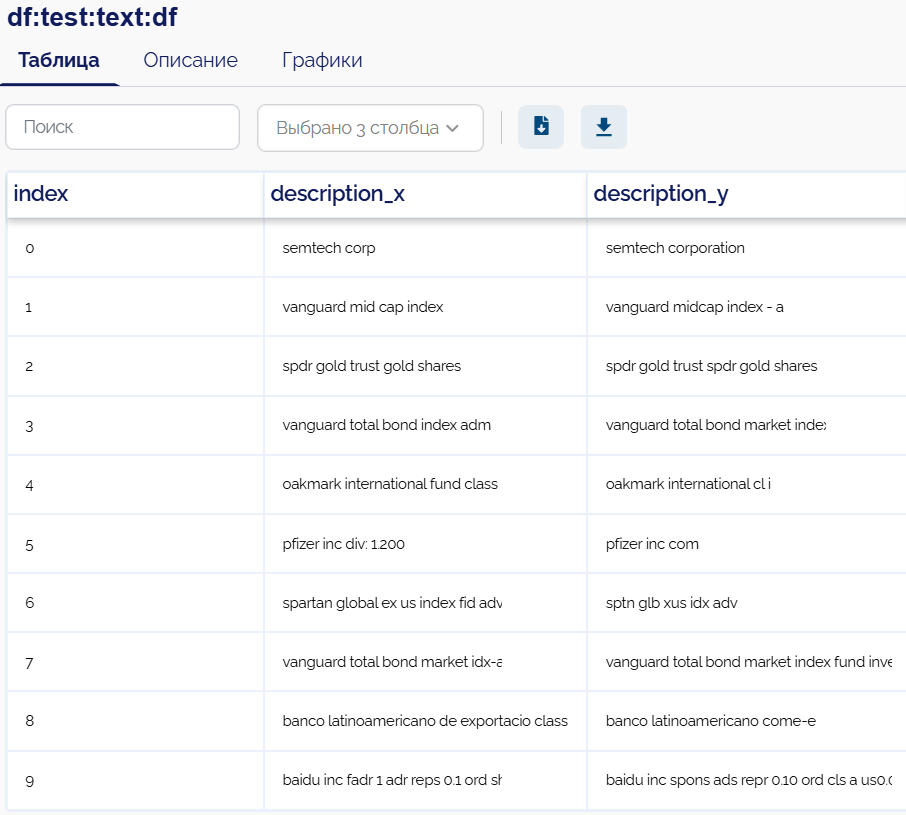
Для примера будем рассматривать следующий датасет с Kaggle: Text Similarity
Создадим граф со следующей структурой:
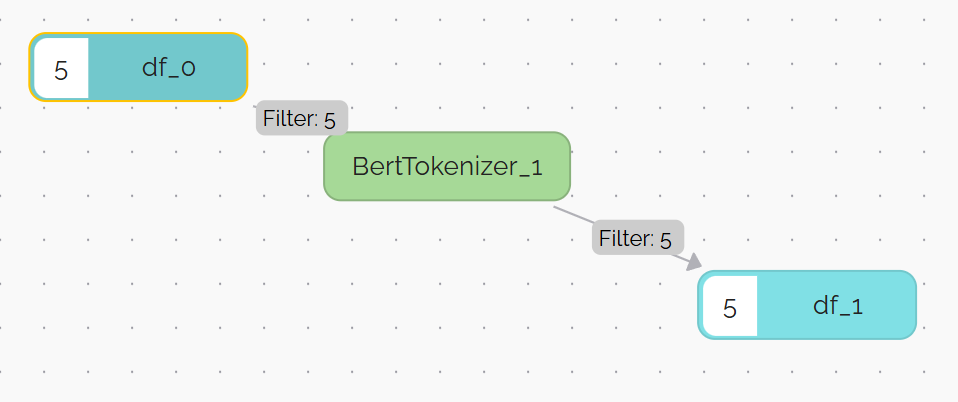
В узле df_0 содержатся следующие данные:
В узле BertTokenizer_1 выбран следующий параметр:
* columns = description_x - целевая колонка с документами.

На выходе, в узле df_1 имеем следующие данные:
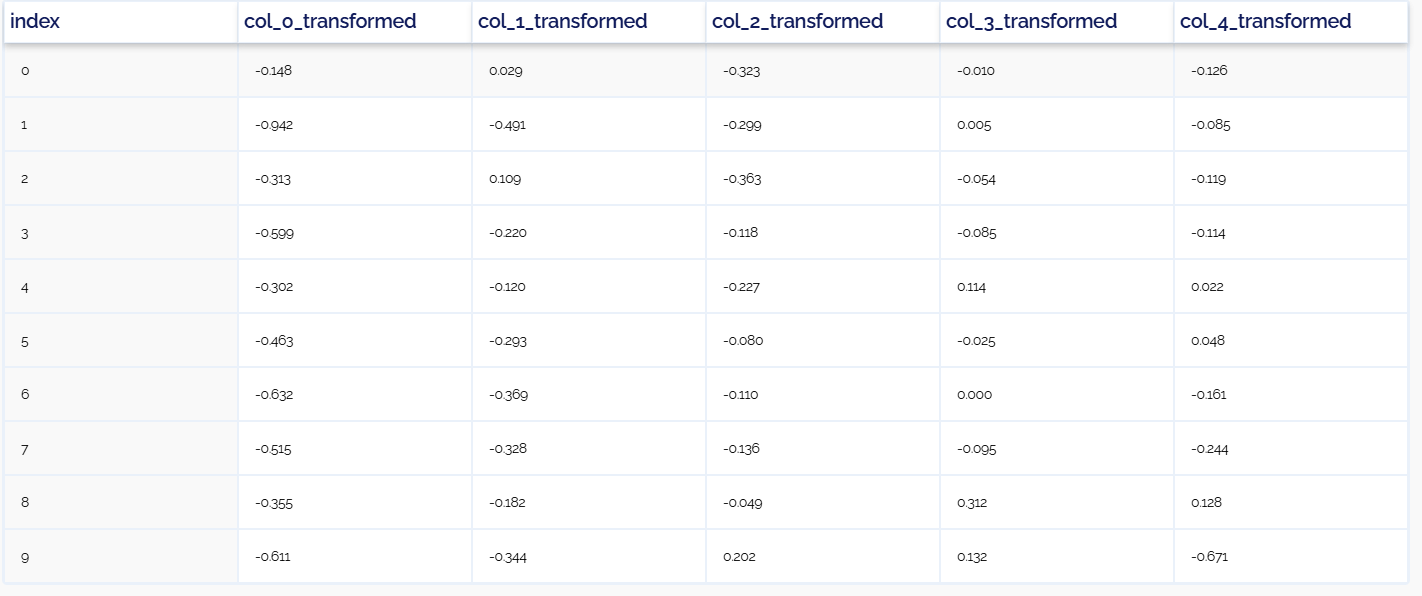 768
768
Данная таблица представляет собой матрицу, колонки которого представляют собой токенизированные векторы, составленные из словаря модели BERT. Колонки имеют следующую структуру названия - col_{n_feature}_transformed.
Далее данную матрицу можно использовать, например для классификации текста.
Модель "BertClassifier"
BertClassifier используется для бинарной или многоклассовой классификации документов с текстами.
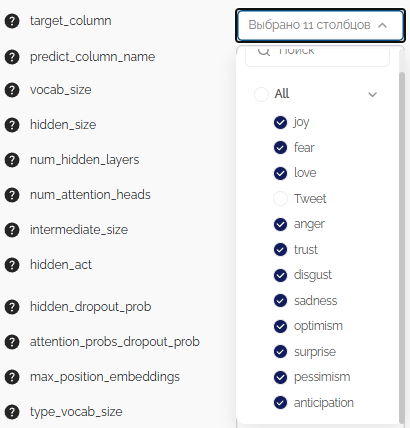
Модель "BertClassifier" имеет следующие параметры:
- target_column - Целевые (многоклассовая) или целевая (бинарная) колонки для классификации.
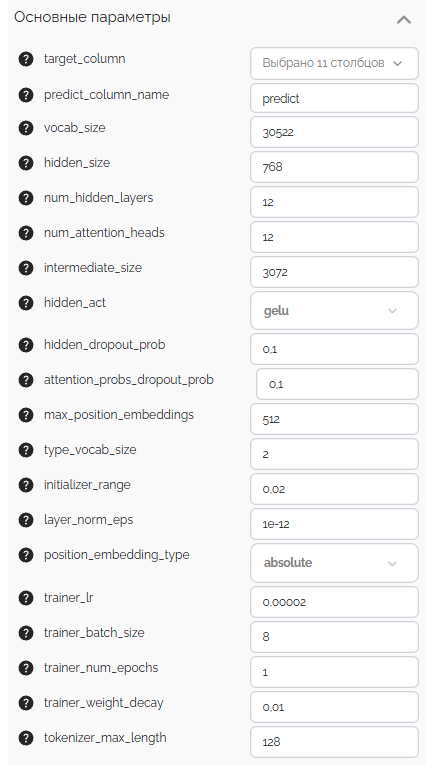
- vocab_size - Размер словаря модели BERT. Определяет количество различных токенов, которые могут быть представлены входными идентификаторами (inputs_ids), переданными при вызове BertModel. (по умолчанию 30522).
- hidden_size - Размерность слоев кодировщика и слоя пула. (по умолчанию 768).
- num_hidden_layers - Количество скрытых слоев в кодировщике Transformer. (по умолчанию 12).
- num_attention_heads - Количество голов внимания в каждом слое внимания кодировщика Transformer. (по умолчанию 12).
- intermediate_size - Размерность промежуточного (т.е. feed-forward) слоя в кодировщике Transformer. (по умолчанию 3072).
- hidden_act - Нелинейная функция активации (функция или строка) в кодировщике и пулере. (по умолчанию gelu).
+ gelu - Она сглаживает значения и считается более эффективной для трансформеров, чем relu. Формула: x * 0.5 * (1 + erf(x / sqrt(2))), где erf — функция ошибок.
+ relu - Простая и популярная функция активации. Формула: max(0, x).
+ silu - Обеспечивает плавный переход и улучшает обучение в некоторых задачах. Формула: x * sigmoid(x), где sigmoid(x) = 1 / (1 + exp(-x)).
+ gelu_new - Это модифицированная версия gelu, которая использует упрощённую формулу: 0.5 * x * (1 + tanh(sqrt(2 / pi) * (x + 0.044715 * x^3))).
hidden_dropout_prob- Вероятность dropout для всех полностью связанных слоев в эмбеддингах, кодировщике и пулере. (по умолчанию0.1).attention_probs_dropout_prob- Коэффициент dropout для вероятностей внимания. (по умолчанию0.1).max_position_embeddings- Максимальная длина последовательности, с которой эта модель может работать. (по умолчанию512).type_vocab_size- Размер словаря для token_type_ids, переданных при вызове BertModel. (по умолчанию2).initializer_range- Стандартное отклонение для truncated_normal_initializer при инициализации всех весовых матриц. (по умолчанию0.02).layer_norm_eps- Эпсилон, используемый в слоях нормализации. (по умолчанию1e-12).position_embedding_type- Тип позиционного эмбеддинга, который будет использоваться. (по умолчаниюabsolute).absolute- Используются абсолютные позиционные эмбеддинги..relative_key- Используются относительные позиционные эмбеддинги, которые зависят от расстояния между токенами.-
relative_key_query- Расширение relative_key, где относительная позиционная информация добавляется как к ключам (key), так и к запросам (query) в механизме внимания. -
trainer_lr- Скорость обучения для оптимизатора. (по умолчанию2e-5). trainer_batch_size- Размер батча для обучения. (по умолчанию8).trainer_num_epochs- Количество эпох для обучения. (по умолчанию5).trainer_weight_decay- Коэффициент регуляризации (weight decay) для оптимизатора. (по умолчанию0.01).tokenizer_max_length- Максимальная длина входных последовательностей. (по умолчанию128).
Данные на вход:
На вход модели для обучения должен поступать датасет, в котором: - Одна колонка с текстовыми документами для классификации - Одна или несколько целевых колонок с классами
Выходной результат:
Модель возвращает предсказания для текстовых документов с колонками-классами, на которых она обучалась.
Пример использования модели:
Для примера будем рассматривать следующий датасет с Kaggle: sem eval 2018 task 1
Создадим граф со следующей структурой:
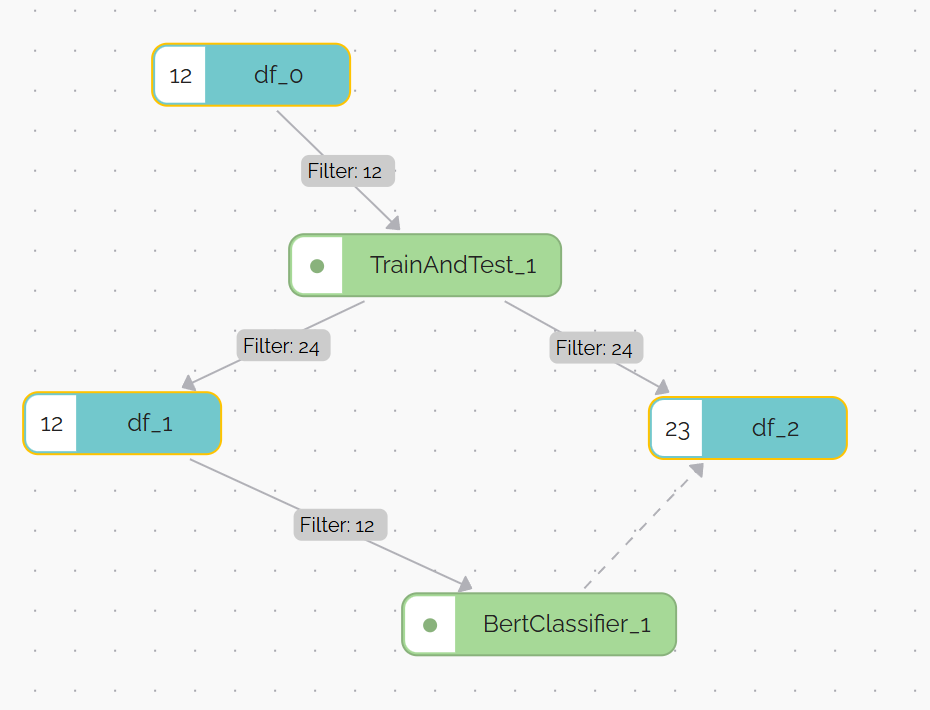
В узле df_0 содержатся следующие данные:
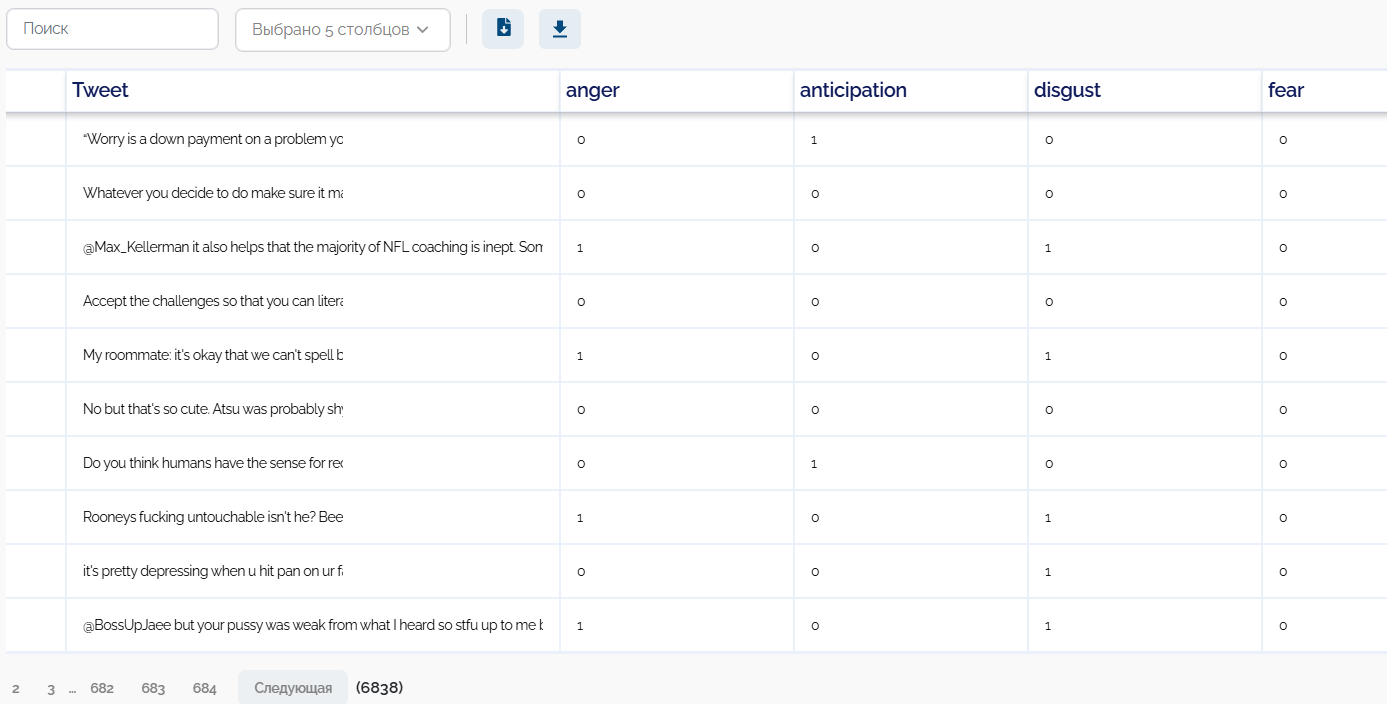
Используем узел TrainAndTest_1 для разбиения данных на обучающую и тестовую выборку. * В узле df_1 - тренировочные данные. * В узле df_2 - тестовые данные.
В узле BertClassifier_1 были выбраны параметры по умолчанию.
Однако была выбрана одна эпоха:
* trainer_num_epochs = 1 - для более быстрого обучения.
На выходе, в узле df_2 имеем следующие данные:
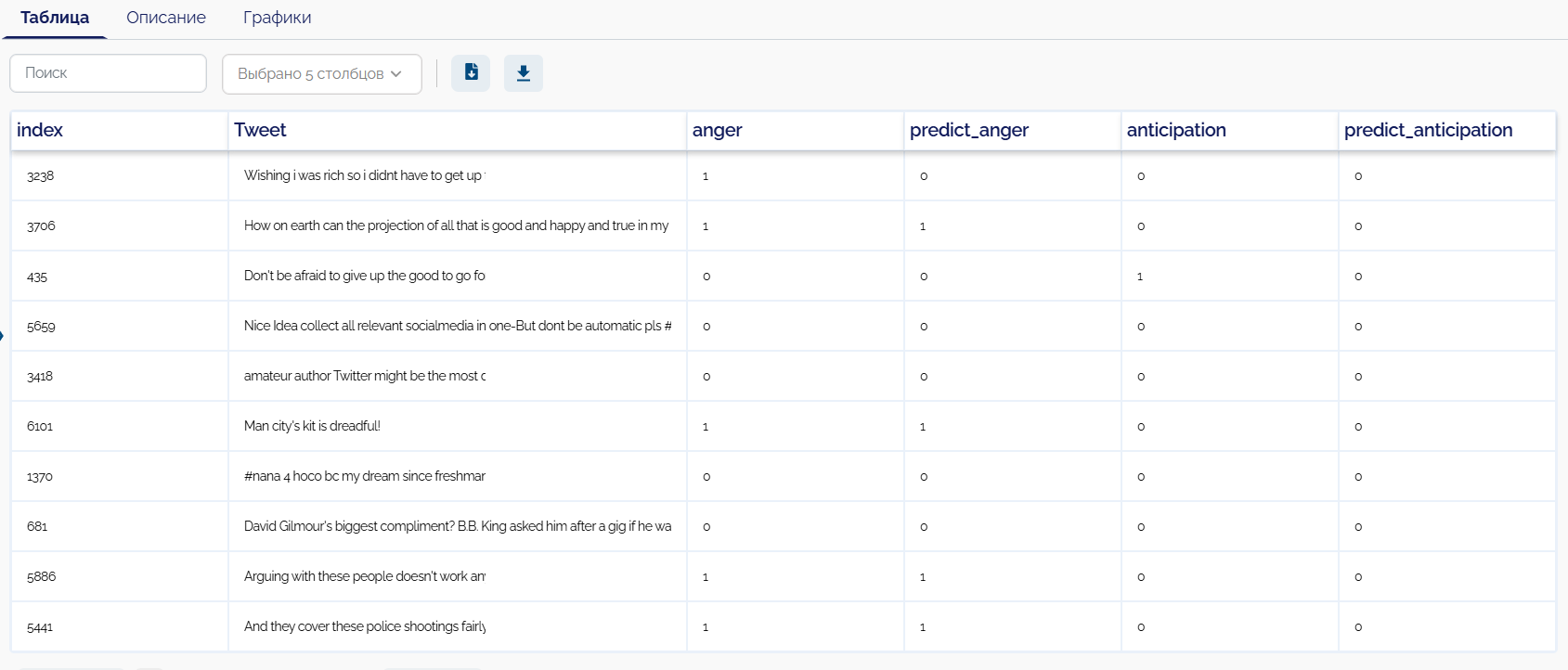
В данной таблице находится начальная колонка с текстовыми документами и целевые колонки, а также предсказания из модели BertClassifier.
Для упрощенного вида на изборажении указаны не все таргеты и предсказания модели.