Преобразование данных на платформе SMILE
Преобразование данных - один из важнейших процессов при решении задач машинного обучения. Когда классические методы не помогают, необходимо вручную извлекать полезную информацию из признаков путем преобразований данных. В данном разделе рассмотрено применение моделей группы DataframeOperations.
Модель "DataframeRename"
Модель предназначена для переименования столбцов в наборе данных.
Модель "DataframeRename" будет иметь в параметрах соответствующие входному набору данных столбцы с возможностью для каждого из них задать новое название.
Модель "DataframeMath"
Модель позволяет преобразовывать данные используя математические операции, как одного столбца, так и нескольких столбцов.
Модель "DataframeMath" имеет следующие параметры:
- select_columns_by - принцип выбора столбцов для производимого действия:
- custom - логика определения столбцов зависит от параметра "expression";
- name - выбор столбцов по названию из текущего списка. При выборе данного столбца необходимо будет заполнить параметр "column_names", в котором будут указаны столбцы для преобразования;
- type - выбор столбцов в зависимости от типа данных. При выборе данного столбца необходимо будет заполнить параметр "column_types", в котором будут указаны типы данных в столбцах для преобразования;
- return_col_name - название возвращаемых после преобразования столбцов;
- expression - произвольное пользовательское выражение по правилам синтаксиса "Pandas"
Пример нормализации значений
На примере набора данных Titanic - Machine learning from disaster рассмотрим нормализацию данных.
Необходимо нормализовать значения столбца Age в ручном режиме с помощью параметра expression.
Для обращения к конкретному столбцу будем использовать следующее выражение:
${Название столбца}
Для данного необходимо заполнить параметры модели DataframeMath следующим образом:
- select_columns_by -
CUSTOM; - return_col_name -
age_normalized; - expression -
(${Age}-${Age}.min())/(${Age}.max)()-${Age}.min())
После выполнения модели в набор данных будет добавлен столбец age_normalized, в котором будут находиться значения, нормализованные
согласно нашему выражению.
Пример логарифмического преобразования нескольких признаков
На примере набора данных Titanic - Machine learning from disaster рассмотрим логарифмическое преобразование на примере выбора столбцов по названию.
Для данного необходимо заполнить параметры модели DataframeMath следующим образом:
- select_columns_by -
NAME;- column_names - выбрать столбцы вручную, значения которых необходимо прологарифмировать;
- return_col_name -
_sin; - expression -
np.sin(${__serial__})
В данном случае вместо конкретного столбца, требуется ввести обращение
__serial__для применения логарифмического преобразования ко всем столбцам выбранного типа данных
Пример изменения признаков одного типа данных
На примере набора данных Titanic - Machine learning from disaster рассмотрим преобразование данных вещественного типа в целочисленный.
Вещественный тип данных представляет собой числа в виде десятичной дроби, а целочисленные представляют собой числа без дробной части
Для данного преобразования необходимо заполнить параметры модели DataframeMath следующим образом:
- select_columns_by -
TYPE;- column_types -
float(вещественный тип данных);
- column_types -
- return_col_name -
to_int; - expression -
${__serial__}.astype(int)
Пример сортировки данных по индексу или значению
На примере набора данных Titanic - Machine learning from disaster рассмотрим сортировку данных.
Для единовременного обращения к целому набору данных используется оператор __df
Применение сортировки возвращает в наборе данных все столбцы с постфиксом
_transformed, поэтому параметрreturn_col_nameигнорируется
Для сортировки набора данных по индексу необходимо заполнить параметры модели DataframeMath следующим образом:
- select_columns_by -
CUSTOM; - expression -
${__df}.sort_index()
Для сортировки набора данных по значениям столбца необходимо заполнить параметры модели DataframeMath следующим образом:
- select_columns_by -
CUSTOM; - expression -
${__df}.sort_values(['Age'])
Модель "DataframeFilter"
Модель предназначается для фильтрации данных по отдельным столбцам или индексу.
Модель "DataframeFilter" имеет следующие параметры:
- column - выбор столбца, значения которого будут сравниваться для фильтрации
- condition - условия сравнений, представленные в виде набора математических операторов
- column_to - столбец, с которым происходит сравнение, по умолчанию заполняется значением "empty", что подразумевает сравнение с значением параметра "value"
- value - значение для сравнения с условием, которое не относится непосредственно к набору данных
- expression - произвольное пользовательское выражение по правилам синтаксиса "Pandas", при его заполнении остальные параметры будут проигнорированы
- reset_index - сброс индекса после фильтрации
Пример фильтрации по условию
На примере набора данных Titanic - Machine learning from disaster рассмотрим фильтрацию данных пользователей по возрасту.
Необходимо отфильтровать данные людей, возраст которых больше 35 лет.
Для данного преобразования необходимо заполнить параметры модели следующим образом:
- column -
Age; - condition -
>; - column_to -
empty; - value -
35; - reset_index -
false;
Пример фильтрации с помощью выражения
На примере набора данных Titanic - Machine learning from disaster рассмотрим фильтрацию данных пользовательским выражением.
Необходимо отфильтровать данные людей, возраст которых больше 35 лет и пол женский.
Для данного преобразования необходимо заполнить параметр expression модели следующим образом:
- expression -
(${Age}>35)&(${Gender}=='Female')
В случае наличия синтаксических ошибок в выражениях или отсутствия данных после фильтрации платформа SMILE будет уведомлять с помощью сообщений в узле модели
Модель возвращает отфильтрованный набор данных с идентичными названиями столбцов.
Модель "DataframeGroupBy"
Модель предназначается для группировки данных внутри одного из наборов.
Модель "DataframeGroupBy" имеет следующие параметры:
- group-by - выбор столбцов для группировки;
- as-index - установление выбранного столбца в параметре "group_by" в качестве индекса выходного набора данных. В случае выбора
столбца группировки, как индекса, доступ обращения к нему напрямую в выходном наборе данных исчезнет;
Следующие параметры позволяют производить операции с выбранными столбцами исходного набора данных и формируют в выходном наборе данных соответствующее количество новых столбцов для каждого уникального выбора в параметре модели
- operation-count - выбор столбцов для подсчета количества значений;
- operation-min - выбор столбцов для отображения минимального значения;
- operation-max - выбор столбцов для отображения максимального значения;
- operation-sum - выбор столбцов для отображения суммы значений;
- operation-first- выбор столбцов для отображения первого значения;
- operation-last - выбор столбцов для отображения последнего значения;
- operation-mean - выбор столбцов для отображения среднего значения;
- operation-median- выбор столбцов для отображения медианного значения;
- operation-std - выбор столбцов для отображения стандартного отклонения значений в столбце;
Пример группировки данных
На примере набора данных Titanic - Machine learning from disaster рассмотрим группировку данных.
Необходимо сгруппировать данные людей, чтобы отобразить для мужского и женского пола:
- подсчет количества значений в столбце возраст;
- максимальный возраст;
- минимальный возраст;
Для данного преобразования необходимо заполнить параметры модели следующим образом:
- group-by -
Gender; - as-index -
false; - operation-count -
Age; - operation-max -
Age; - operation-min -
Age;
Модель "DataframeGroupByDate"
Модель предназначается для группировки данных внутри одного из наборов по датам. Модель работает аналогично "DataframeGroupBy", но с расширенным функционалом для работы с группировкой по датам.
Модель "DataframeGroupByDate" имеет следующие параметры:
- group-by - выбор столбца дат для группировки;
- freq - частота группировки:
- Millisecond - по миллисекундам
- Second - по секундам
- Minute - по минутам
- Day - по дням
- Week - по неделям
- Month - по месяцам
- Year - по годам
- freq_num - частота группировки внутри "freq", то есть при параметре freq_num=1 и freq='Year' - группировка будет по годам (за каждый год), а при freq_num=2 и freq='Year' - группировка будет по годам с шагом в 2 года (например 2014, 2016 и 2018);
- convention - параметр, отвечающий за группировку значений в начале или в конце временного промежутка "freq";
- Start - в начале
- End - в конце
- as-index - установление выбранного столбца в параметре "group_by" в качестве индекса выходного набора данных. В случае выбора
столбца группировки, как индекса, доступ обращения к нему напрямую в выходном наборе данных исчезнет;
Следующие параметры позволяют производить операции с выбранными столбцами исходного набора данных и формируют в выходном наборе данных соответствующее количество новых столбцов для каждого уникального выбора в параметре модели
- operation-count - выбор столбцов для подсчета количества значений;
- operation-min - выбор столбцов для отображения минимального значения;
- operation-max - выбор столбцов для отображения максимального значения;
- operation-sum - выбор столбцов для отображения суммы значений;
- operation-first- выбор столбцов для отображения первого значения;
- operation-last - выбор столбцов для отображения последнего значения;
- operation-mean - выбор столбцов для отображения среднего значения;
- operation-median- выбор столбцов для отображения медианного значения;
- operation-std - выбор столбцов для отображения стандартного отклонения значений в столбце;
Пример группировки данных
На примере набора данных Retail Data Analytics
рассмотрим группировку данных по датам.
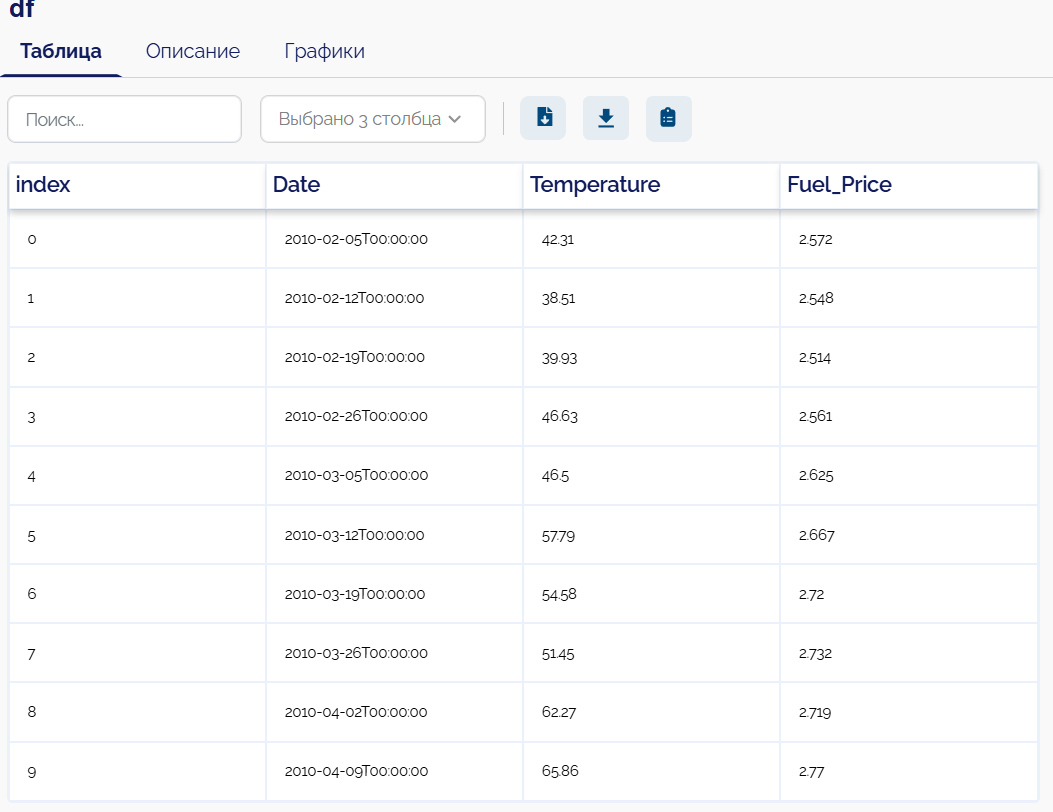
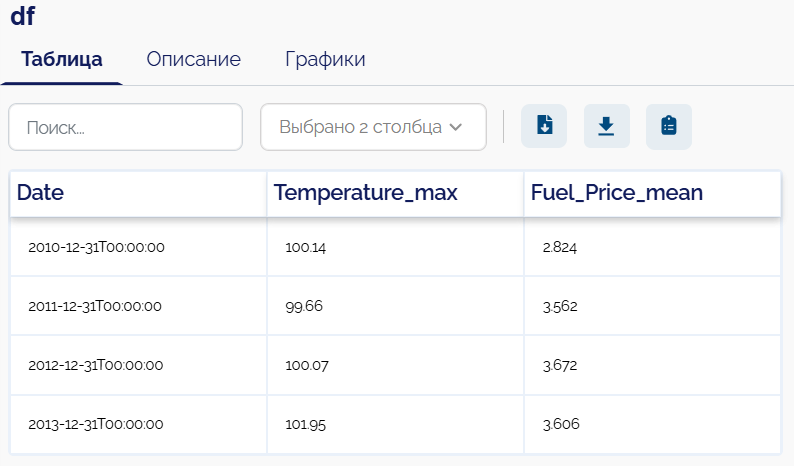
Необходимо сгруппировать данные по годам и отобразить максимальную температуру за год и среднюю стоимость топлива
Для данного преобразования необходимо заполнить параметры модели следующим образом:
- group-by -
Date; - freq -
Year; - freq_num -
1; - convention -
End; - as-index -
True; - operation-max -
Temperature; - operation-mean -
Fuel_price;
На выходе получаем следующие данные:
Модель "DataframeReplace"
Модель предназначается для замены конкретных значений в наборе данных на пользовательские.
Модель "DataframeReplace" имеет следующие параметры:
- columns - столбцы, в которых необходимо заменить значения;
- to_replace - значения, которые необходимо заменить. Несколько значений могут введены последовательно через знак запятой
,; - result - пользовательское значение, на которое нужно заменить исходные данные;
После применения модели к набору данных, преобразованные столбцы будут помечены постфиксом
_transformed
Пример замены числовых значений
На примере набора данных Titanic - Machine learning from disaster рассмотрим замену значений в наборе данных.
Необходимо в столбце Pclass заменить значения "1", "2", "3" на значение 0.
Для данного преобразования необходимо заполнить параметры модели следующим образом:
- columns -
PClass; - to_replace -
1,2,3; - result -
0;
Пример замены значений в строках
На примере предобработанного набора данных "Титаник" рассмотрим замену значений в наборе данных. Необходимо в столбце "Титул" заменить часть значений на "Другое".
Для данного преобразования необходимо заполнить параметры модели следующим образом:
- columns -
titul; - to_replace -
Capt, Col, Don, Dr, Jonkheer, Major; - result -
Other;
Модель "DataframeMerge"
Модель предназначена для объединения наборов данных между собой по столбцам в один конечный набор данных.
Модель DataframeMerge имеет следующие параметры:
- left_on - столбцы для слияния из таблицы "слева", соответствующие столбцам из "правой" таблицы;
- right_on - столбцы для слияния из таблицы "справа", соответствующие столбцам из "левой" таблицы;
- left_index - слияние по индексу из таблицы "слева";
- right_index - слияние по индексу из таблицы "справа";
- on - выбор столбца, находящегося в "левой" и "правой" таблице для слияния по нему;
- how - выбор способа слияния таблиц
- left - сохраняет все значения из "левой" таблицы и подставляет пересекающиеся значения из "правой" таблицы.
В случае, когда пересекающиеся значения отсутствуют и в "правой" таблице, они заполняются пустыми
Nan значениями. - right - сохраняет все значения из "правой" таблицы и подставляет пересекающиеся значения из "левой" таблицы.
В случае, когда пересекающиеся значения отсутствуют и в "левой" таблице, они заполняются пустыми
Nan значениями. - outer - объединение всех значений;
- inner - объединение значений, которые присутствуют в обеих таблицах;
- cross - декартовое произведение "левой" и "правой" таблиц;
- left - сохраняет все значения из "левой" таблицы и подставляет пересекающиеся значения из "правой" таблицы.
В случае, когда пересекающиеся значения отсутствуют и в "правой" таблице, они заполняются пустыми
- left_suffix - постфикс, добавляемый к столбцам выходного набора данных, взятых из "левой" таблицы;
- right_suffix - постфикс, добавляемый к столбцам выходного набора данных, взятых из "правой" таблицы;
Пример слияния таблиц
На примере набора данных "О ценах на фрукты" рассмотрим слияние двух наборов данных.
Необходимо объединить данные из файлов apple_renamed и apricot_renamed по столбцам price_max и price_min
Для данного преобразования необходимо заполнить параметры модели следующим образом:
- on -
apple_price_max, apple_price_min, apricot_price_max, apricot_price_min; - how -
outer;
В случае совпадения столбцов в наборах данных можно использовать параметры
left_onиright_on
Модель "DataframeConcat"
Модель предназначена для объединения наборов данных между собой по строкам в один конечный набор данных.
Модель "DataframeConcat" имеет следующие параметры:
- reset_index - сброс индекса у выходного набора данных;
- axis - выбор оси для объединения:
- index - вертикальная ось, строки будут добавлены в текущий набор данных;
- columns - горизонтальная ось, строки будут добавлены, аналогично модели
DataframeMerge
- join - выбор способа объединения:
- inner - объединение строк, пересекающихся столбцов;
- outer - объединение всех строк, с заполнением отсутствующих значений пустыми;
- ignore_index - игнор индекса;
- sort_index - сортировка по индексу после объединения наборов данных;
Пример конкатинации таблиц
На примере набора данных "О ценах на фрукты" рассмотрим конкатинацию таблиц.
Необходимо соединить строки таблицы apple и apricot со сбросом индекса.
Для данного преобразования необходимо заполнить параметры модели следующим образом:
- reset_index -
true; - axis -
index; - join -
inner; - ignore_index -
false; - sort_index -
false;
Модель "DataframeReset"
Модель предназначена для сброса индексов набора данных.
- axis - направление сброса данных:
- index - сброс по вертикали (индексов);
- columns - сброс по горизонтали (названия столбцов);
- drop - сброс индекса у выходного набора данных;
Модель может быть полезна в случаях работы с наборами данных, в которых проводились построчные изменения (конкатинация, смещение и другие) для сброса индексов или названий столбцов всего набора данных.
Модель "DropByNone"
Модель предназначены для удаления строк, выбранные столбцы которых содержат пустые значения.
Модель "DropByNone" имеет следующие параметры:
- columns - выбор столбцов, в которых проводится поиск пустых значений для дальнейшего удаления строк;
По умолчанию модель "DropByNone" выбирает в параметре "columns" все столбцы, в которых есть пустые значения. При необходимости столбцы могут быть выбраны вручную.
Пример удаления пустых значений
На примере набора данных Titanic - Machine learning from disaster рассмотрим удаление строк с пустыми значениями.
Необходимо удалить строки, которые содержат пропуски в столбцах Age, Cabin, Embarked
Для данного преобразования необходимо заполнить параметры модели следующим образом:
- columns -
Age, Cabin, Embarked;
Модель "DropByValue"
Модель предназначены для удаления строк, выбранные столбцы которых содержат конкретные значения.
Модель "DropByValue" имеет следующие параметры:
- columns - выбор столбцов, в которых проводится поиск пользовательских значений для дальнейшего удаления строк;
- value - значения для поиска в столбцах, несколько значений можно ввести через
,;
Пример удаления конкретных значений
На примере набора данных Titanic - Machine learning from disaster рассмотрим удаление строк с конкретными значениями.
Необходимо удалить строки, которые содержат значения male, female.
Для данного преобразования необходимо заполнить параметры модели следующим образом:
- columns -
All, все столбцы набора данных; - value -
male, female;
При этом в данном случае будут удалены все столбцы, поэтому выходного набора данных не будет существовать