SHAP Beeswarm
Как интерпретировать Beeswarm-график?
🟣 Цвет маркеров
Цветовая шкала маркеров соответствует нормированным значениям признаков, а не их важности.
В классической палитре SHAP:
- 🔵 Синий — низкое значение признака
- 🔴 Красный/розовый — высокое значение признака
- 🟣 Фиолетовые и промежуточные цвета — промежуточные значения
⚠️ Цвет не отражает важность признака — он показывает его нормализованное физическое значение.
↔️ Ось X = SHAP value
Положение точки по оси X показывает, насколько и в какую сторону признак влияет на предсказание.
- ➕ Справа от 0 — признак повышает предсказание
- ➖ Слева от 0 — признак понижает предсказание
Примеры:
- Красная точка на +1.5 → высокий признак, сильно увеличил результат
- Синяя точка на –2.0 → низкий признак, сильно уменьшил результат
↕️ Ось Y = Признаки (фичи)
Каждая строка на графике — это отдельный признак. Чем выше он расположен, тем больше его средняя абсолютная важность (mean(|SHAP|)).
- Верхние признаки — наиболее важны
- Нижние признаки — менее значимы
🐝 Распределение точек внутри признака
Распределение точек напоминает роение пчёл — отсюда и название Beeswarm.
- Каждая точка — это отдельный объект (пример) из набора данных
- Вертикальное отклонение точек — это джиттер, добавленный для предотвращения наложения и улучшения читаемости графика
💡 Важно: вертикальная позиция точек не несёт смысловой нагрузки — это просто визуальный приём.
✍️ Пример чтения графика
Рассмотрим строку для признака petal_length (длина лепестка):
- Слева — много синих точек
→ короткие лепестки уменьшают предсказание - Справа — много красных точек
→ длинные лепестки увеличивают предсказание - Центр — фиолетовые/розовые точки с SHAP ≈ 0
→ лепестки среднего размера имеют нейтральный эффект
🧠 Итог: как читать Beeswarm-график
| Элемент | Что означает |
|---|---|
| Цвет точки | Насколько велико значение признака |
| Положение по X | Насколько признак повлиял на результат |
| Положение по Y | Какой это признак и насколько он важен |
| Распределение точек | Как признак влияет на разные объекты |
🧪 Кейс классификации: Iris Dataset
Разберём график на примере набора Iris и модели LogisticRegression.
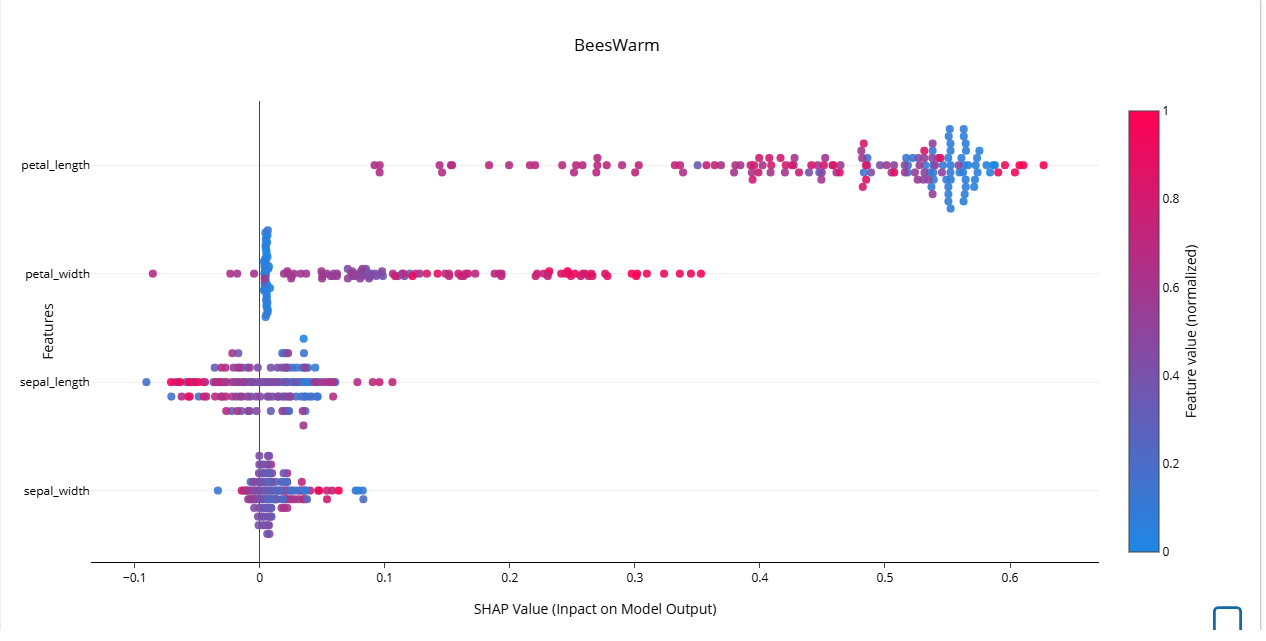
-
Признак
petal_lengthпоказывает сильное смещение точек вправо — он наиболее значим для предсказания.
Признак важен и при высоких, и при низких значениях, что видно по разноцветным точкам. -
В признаке
petal_widthзначимы только высокие значения — синих точек почти нет, значит, низкие значения не влияют на результат. -
Признаки
sepal_lengthиsepal_widthпочти не влияют — большинство точек сосредоточены вокруг SHAP ≈ 0.
При этом вsepal_lengthвидно, что высокие значения (красные точки) дают отрицательный SHAP — они могут понизить вероятность предсказания.
🧪 Кейс регрессии: California Housing
Рассмотрим SHAP Beeswarm-график для задачи прогноза стоимости недвижимости на основе датасета California Housing с моделью KNeighborsRegressor.
- Целевая переменная: медианная стоимость домов в долларах
- Один объект: блочная группа домов
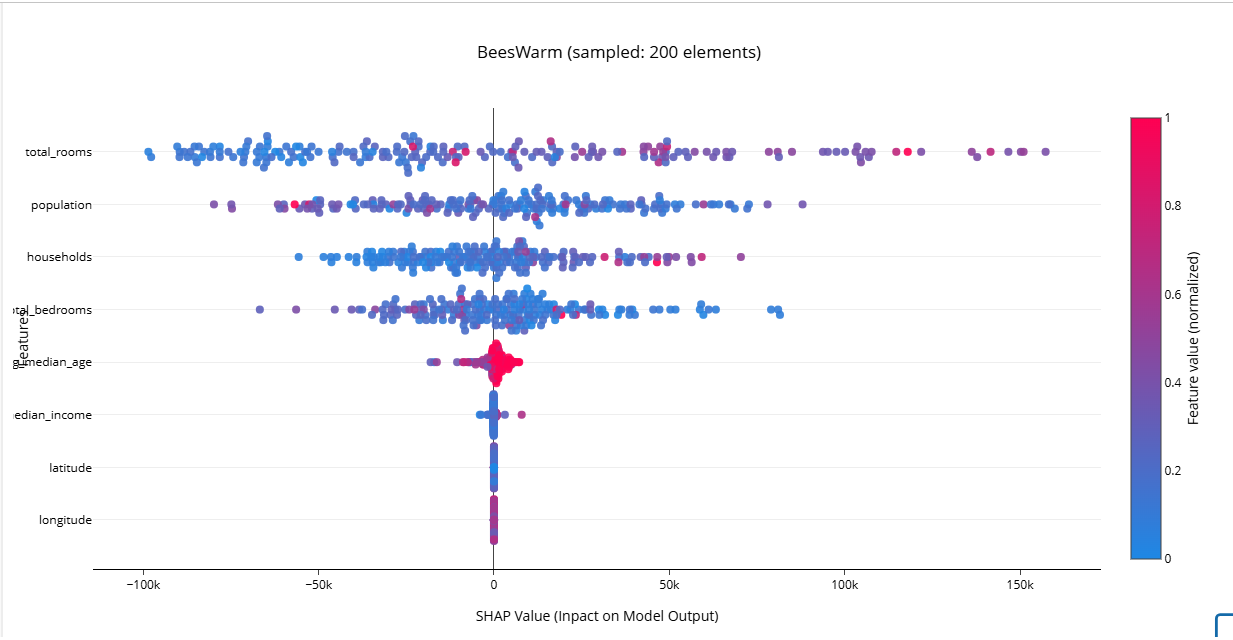
Анализ:
- Признак
total_rooms— самый значимый. - Фиолетовые точки справа → средние значения увеличивают предсказание на 100k+ $
-
Синие точки слева → низкие значения уменьшают предсказание
-
Признаки
latitudeиlongitudeне дают существенного вклада
→ логично, т.к. в "сыром" виде они малоинформативны без фича-инжиниринга (например, кластеров или расстояний до побережья) -
median_incomeиmedian_age— почти не влияют
→ вклад в цену редко превышает ±10k $
🔍 Вывод
- Без feature engineering не обойтись.
- Нужно унифицировать признаки: сейчас есть и медианные, и абсолютные показатели.
- Так как целевой показатель — медианная стоимость, признаки с абсолютными значениями (например,
total_rooms) желательно привести к медианным или средним на дом (например,rooms_per_household).